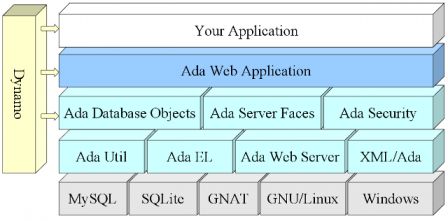
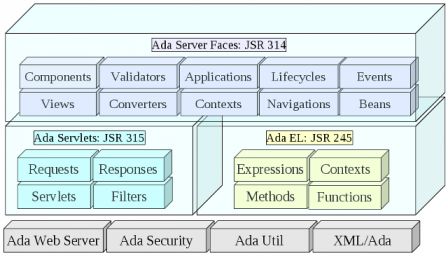
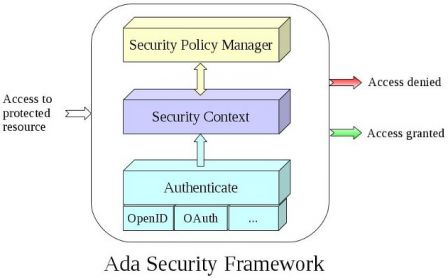
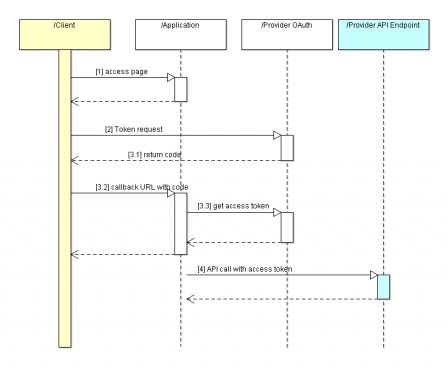
When you run several web applications implemented in various languages (php, Java, Ada), you end up with some integration issue. The PHP application runs within an Apache Server, the Java application must runs in a Java web server (Tomcat, Jetty), and the Ada application executes within the Ada Web Server. Each of these web servers need a distinct listening port or distinct IP address. Integration of several web servers on the same host, is often done by using a front-end server that handles all incomming requests and dispatches them if necessary to other web servers.
In this article I describe the way I have integrated the Ada Web Server. The Apache Server is the front-end server that serves the PHP files as well as the static files and it redirects some requests to the Ada Web Server.
Virtual host definition
The Apache Server can run more than one web site on a single machine. The Virtual hosts can be IP-based or name-based. We will use the later because it provides a greater scalability. The virtual host definition is bound to the server IP address and the listening port.
<VirtualHost *:80>
ServerAdmin webmaster@localhost
ServerAlias demo.vacs.fr
ServerName demo.vacs.fr
...
LogLevel warn
ErrorLog /var/log/apache2/demo-error.log
CustomLog /var/log/apache2/demo-access.log combined
</VirtualHost>
The ServerName part is matched against the Host: request header that is received by the Apache server.
The ErrorLog and CustomLog are not part of the virtual hosts definition but they allow to use dedicated logs which is useful for trouble shotting issues.
Setting up the proxy
The Apache mod_proxy module must be enabled. This is the module that will redirect the incomming requests to the Ada Web Server.
<Proxy *>
AddDefaultCharset off
Order allow,deny
Allow from all
</Proxy>
Redirection rules
The Apache mod_rewrite module must be enabled.
RewriteEngine On
A first set of rewriting rules will redirect the request to dynamic pages to the Ada Web Server. The [P] flag activates the proxy and redirects the request. The Ada Web Server is running on the same host but is using port 8080.
# Let AWS serve the dynamic HTML pages.
RewriteRule ^/demo/(.*).html$ http://localhost:8080/demo/$1.html [P]
RewriteRule ^/demo/auth/(.*)$ http://localhost:8080/demo/auth/$1 [P]
RewriteRule ^/demo/statistics.xml$ http://localhost:8080/demo/statistics.xml [P]
When the request is redirected, the mod_proxy will add a set of headers that can be used within AWS if necessary.
Via: 1.1 demo.vacs.fr
X-Forwarded-For: 31.39.214.181
X-Forwarded-Host: demo.vacs.fr
X-Forwarded-Server: demo.vacs.fr
The X-Forwarded-For: header indicates the IP address of client.
Static files
Static files like images, CSS and javascript files can be served by the Apache front-end server. This is faster than proxying these requests to the Ada Web Server. At the same time we can setup some expiration and cache headers sent in the response (Expires: and Cache-Control: respectively). The definition below only deal with images that are accessed from the /demo/images/ URL component. The Alias directive tells you how to map the URL to the directory on the file system that holds the files.
Alias /demo/images/ "/home/htdocs.demo/web/images/"
<Directory "/home/htdocs.demo/web/images/">
Options -Indexes +FollowSymLinks
# Do not check for .htaccess (perf. improvement)
AllowOverride None
Order allow,deny
allow from all
# enable expirations
ExpiresActive On
# Activate the browser caching
# (CSS, images and scripts should not change)
ExpiresByType image/png A1296000
ExpiresByType image/gif A1296000
ExpiresByType image/jpg A1296000
</Directory>
This kind of definition is repeated for each set of static files (javascript and css).
Proxy Overhead
The proxy adds a small overhead that you can measure by using the Apache Benchmark tool. A first run is done on AWS and another on Apache.
ab -n 1000 http://localhost:8080/demo/compute.html
ab -n 1000 http://demo.vacs.fr/demo/compute.html
The overhead will depend on the application and the page being served. On this machine, the AWS server can process arround 720 requests/sec and this is reduced to 550 requests/sec through the Apache front-end (23% decrease).
![Memory consumption with Massif [before]](/images/Ada/.massif-before_m.jpg)
![Memory consumption with Massif [after]](/images/Ada/.massif-after_m.jpg)