After one year of daily and weekly backup using Bacula on a ReadyNAS duo, I wanted to share information about this success story. Bacula is a network backup solution that I installed on a ReadyNAS duo. Bacula allows to make full as well as incremental backups of remote machines. It uses a MySQL database that also runs on the ReadyNAS (see Installing Mysql server on a ReadyNAS duo) and it stores backups on media such as tapes, CDs, DVDs or files.
Backup Architecture
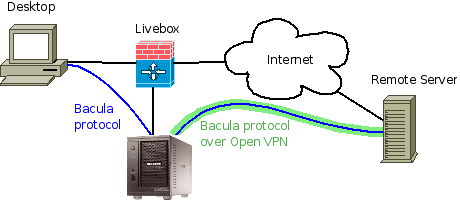
The Bacula software is running directly on the ReadyNAS duo. The backup is configured to backup my desktop which is accessed locally, and it also backups a server running on the Internet (vacs.fr). Since the ReadyNAS is behind my Livebox, it connects to the Internet server by using a secure tunnel with OpenVPN.
The ReadyNAS duo has two 1To hard disks configured as RAID 1 mirrors.
- Bacula director and bacular storage daemons are running on the ReadyNAS duo
- Bacula client is running on each machine that must be backed up (Desktop and Remote Server).
Backup Pools and Strategy
Bacula is configured to create backups on file tapes. Each tape is a flat file stored on the ReadyNAS duo in some directory. I've configured file tapes so that they do not extend 4.3G (so that copying and burning DVDs could be possible).
File tapes are grouped in several pools. Each pool represent a class of backup. My primary backup strategy is split in 3 backup grades:
A-Grade backups represent critical files that must not be lost at all. They represent the files that I really care and for which I want to have one year of backup. The retention policy is set to one year with one full backup per month. In short, it means I can restore the data I had anytime during the last year. Basically it contains my full desktop home directory as well as specific directories (private photos and so on).
B-Grade backups represent less critical files for which I may not need to restore an old version. The retention policy is 180 days. This backup grade is used for software or files that I download from Internet.
C-Grade backups have a 65-days retention policy and they are used for the system. Basically, re-installation of a server or desktop from scratch is always possible but keeping the configuration files in the backup is very helpful.
A Pool is defined for each of these grades:
# A-Grade pool: 1 year retention, 12 full backups (1 full bkp/month)
Pool {
Name = A-Full-Pool
Pool Type = Backup
# Bacula can automatically recycle Volumes
Recycle = yes
AutoPrune = yes # Prune expired volumes
Volume Retention = 360 days
Label Format=A-Full-
# 100 volumes of 4G (expecting 8 volumes/full backup)
Maximum Volumes=100
}
# B-Grade pool: 6 months retention, 3 full backups (1 full bkp/2 months)
Pool {
Name = B-Full-Pool
Pool Type = Backup
Recycle = yes
AutoPrune = yes # Prune expired volumes
Volume Retention = 180 days
Label Format=B-Full-
Maximum Volumes=40
}
# C-Grade pool: 2 months retention, 2 full backups (1 full bkp/45 day)
Pool {
Name = C-Full-Pool
Pool Type = Backup
Recycle = yes
AutoPrune = yes
Volume Retention = 65 days # 2 months
Label Format=C-Full-
# 5 volumes of 4G (expecting 2 volumes/full backup)
Maximum Volumes=5
}
In addition to these pools, an incremental and a differential pool must be defined.
Bacula FileSet
The Bacula FileSet represent the file patterns that have to be backed up. I have defined one FileSet for each machine and backup grade combination. The filesets are compressed. Files matching some patterns are excluded (*.o, *.log, *.bak, *~). The FileSet below is for my desktop and for the A-Grade backup. Directories /home, /data and /photos will be taken into account in the backup.
# List of files to be backed up
FileSet {
Name = "Zebulon A-Grade"
Include {
Options {
signature=SHA1
compression=GZIP
verify = pins1
onefs = yes
WildFile = "*~"
WildFile = "*.bak"
WildFile = "*.log"
WildFile = "*.o"
Exclude = yes
}
File = /home
File = /data
File = /photos
}
}
Other FileSets are defined for the same machine but for different files. They will be used for other backup grades.
Backup Schedule
The schedule defines when the backup has to be executed. Each backup grade has its own schedule. This allows to run B-Grade and C-Grade backups less frequently than A-Grade.
The A-Grade backups have a full backup schedule the first Saturday of each month. A full backup of the desktop takes arround 5 hours and uses 57Go (compressed). A differential backup takes arround 2 hours and uses 10Go (compressed). The incremental backup uses 2-4Go (compressed) and 5 to 15 minutes. (these numbers depend on what is being backed up). The schedule hours are defined according to this.
Schedule {
Name = "Weekly-A-Grade"
Run = Full 1st sat at 23:05
Run = Differential 2nd-5th sun at 22:10
Run = Incremental sun-fri at 22:10
}
Schedule {
Name = "Weekly-B-Grade"
Run = Full jan 1st sat at 23:05
Run = Full mar 1st sat at 23:05
Run = Full may 1st sat at 23:05
Run = Full jul 1st sat at 23:05
Run = Full sep 1st sat at 23:05
Run = Full nov 1st sat at 23:05
Run = Differential 2nd-5th sun at 22:10
Run = Incremental wed at 22:10
}
Schedule {
Name = "Weekly-C-Grade"
Run = Full jan 1st sat at 2:05
Run = Full mar 1st sat at 2:05
Run = Full may 1st sat at 2:05
Run = Full jul 1st sat at 2:05
Run = Full sep 1st sat at 2:05
Run = Full nov 1st sat at 2:05
Run = Differential 2nd-5th sat at 2:10
Run = Incremental sat at 2:10
}
Bacula Job
The Bacula Job describes what must be backed up (FileSets), when (Schedule) and where (Pools). There is one job definition for each fileset.
Job {
Name = "Zebulon-A"
Type = Backup
Client = zebulon-fd
FileSet = "Zebulon A-Grade"
Schedule = "Weekly-A-Grade"
Storage = File
Messages = Standard
Pool = Default
Full Backup Pool = A-Full-Pool
Incremental Backup Pool = Incr-Pool
Differential Backup Pool = Diff-Pool
Priority = 8
}
Some Statistics
After more than one year of backups, the total storage space used is now 599G, each tape is 4.3G. The storage space used by file pools is as follows:
A Grade Full Tapes 73 313Go
B Grade Full Tapes 28 120Go
C Grade Full Tapes 4 17Go
Differential tapes 22 94Go
Incremental tapes 13 55Go
The MySQL database has grown a lot and is quite large. The InnoDB database file only contains the bacula database and it has grown up to 2Go now. The filename table references 885527 records and the path table references 546784 rows.
Conclusion
Bacula is not easy to configure but when you do it right it provides a performant backup solution. To learn more about the configuration, have a look at Bacula Documentation. Installed on a ReadyNAS duo, it proved to be a robust solution for a backup of a small set of machines. You cannot expect big performances during backup or restore. The performance bottleneck is the MySQL database which runs on the ReadyNAS.
Restoring files from the backup is quite easy but this is another story...