How does Ada, Java and Python compare with each other when they are used to connect to a database? This was the main motivation for me to write the SQL Benchmark and write this article.
Ada, Java and Python database access
By Stephane Carrez2018-11-17 14:02:00
The database also has a serious impact on such benchmark and I've measured the following three famous databases:
The purpose of the benchmark is to be able to have a simple comparison between these different databases and different programming languages. For this, a very simple database table is created with only two integer columns one of them being the primary key with auto increment. For example the SQLite table is created with the following SQL:
CREATE table test_simple (
id INTEGER PRIMARY KEY AUTOINCREMENT,
value INTEGER
)
The database table is filled with a simple INSERT statement which is also benchmarked. The goal is not to demonstrate and show the faster insert method, nor the faster query for a given database or language.
Benchmark
The SQL benchmarks are simple and they are implemented in the same way for each language so that we can get a rough comparison between languages for a given database. The SELECT query retrieves all the database table rows but it includes a LIMIT to restrict the number of rows returned. The query is executed with different values for the limit so that a simple graph can be drawn. For each database, the SQL query looks like:
SELECT * FROM test_simple LIMIT 10
The SQL statements are executed 10000 times for SELECT queries, 1000 times for INSERT and 100 times for DROP/CREATE statements.
Each SQL benchmark program generates an XML file that contains the results as well as resource statistics taken from the /proc/self/stat file. An Ada tool is provided to gather the results, prepare the data for plotting and produce an Excel file with the results.
Python code
def execute(self):
self.sql = "SELECT * FROM test_simple LIMIT " + str(self.expect_count)
repeat = self.repeat()
db = self.connection()
stmt = db.cursor()
for i in range(0, repeat):
stmt.execute(self.sql)
row_count = 0
for row in stmt:
row_count = row_count + 1
if row_count != self.expect_count:
raise Exception('Invalid result count:' + str(row_count))
stmt.close()
Java code
public void execute() throws SQLException {
PreparedStatement stmt
= mConnection.prepareStatement("SELECT * FROM test_simple LIMIT " + mExpectCount);
for (int i = 0; i < mRepeat; i++) {
if (stmt.execute()) {
ResultSet rs = stmt.getResultSet();
int count = 0;
while (rs.next()) {
count++;
}
rs.close();
if (count != mExpectCount) {
throw new SQLException("Invalid result count: " + count);
}
} else {
throw new SQLException("No result");
}
}
stmt.close();
}
Ada code
procedure Select_Table_N (Context : in out Context_Type) is
DB : constant ADO.Sessions.Master_Session := Context.Get_Session;
Count : Natural;
Stmt : ADO.Statements.Query_Statement
:= DB.Create_Statement ("SELECT * FROM test_simple LIMIT " & Positive'Image (LIMIT));
begin
for I in 1 .. Context.Repeat loop
Stmt.Execute;
Count := 0;
while Stmt.Has_Elements loop
Count := Count + 1;
Stmt.Next;
end loop;
if Count /= LIMIT then
raise Benchmark_Error with "Invalid result count:" & Natural'Image (Count);
end if;
end loop;
end Select_Table_N;
The benchmark were executed on an Intel i7-3770S CPU @3.10Ghz with 8-cores running Ubuntu 16.04 64-bits. The following database versions are used:
- MariaDB 10.0.36
- PostgreSQL 9.5.14
Resource usage comparison
The first point to note is the fact that both Python and Ada require only one thread to run the SQL benchmark. On its side, the Java VM and database drivers need 20 threads to run.
The second point is not surprising: Java needs 1000% more memory than Ada and Python uses 59% more memory than Ada. What is measured is the the VM RSS size which means this is really the memory that is physically mapped at a given time.
The SQLite database requires less resource than others. The result below don't take into account the resource used by the MariaDB and PostgreSQL servers. At that time, the MariaDB server was using 125Mb and the PostgreSQL server was using 31Mb.
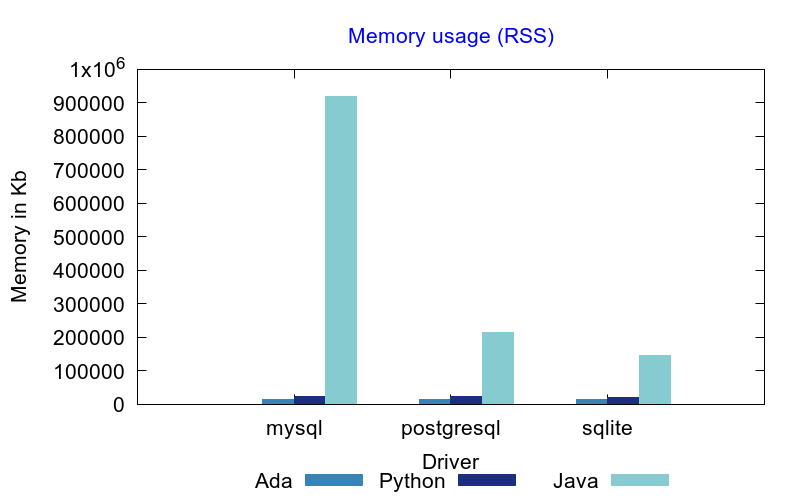
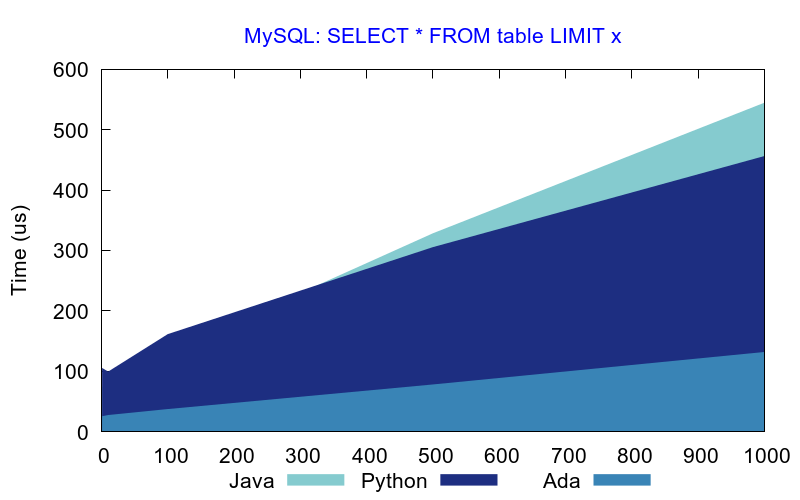
Speed comparison
Looking at the CPU time used to run the benchmark, Ada appears as a clear winner. The Java PostgreSQL driver appears to be very slow at connecting and disconnecting to the database, and this is the main reason why it is slower than others.
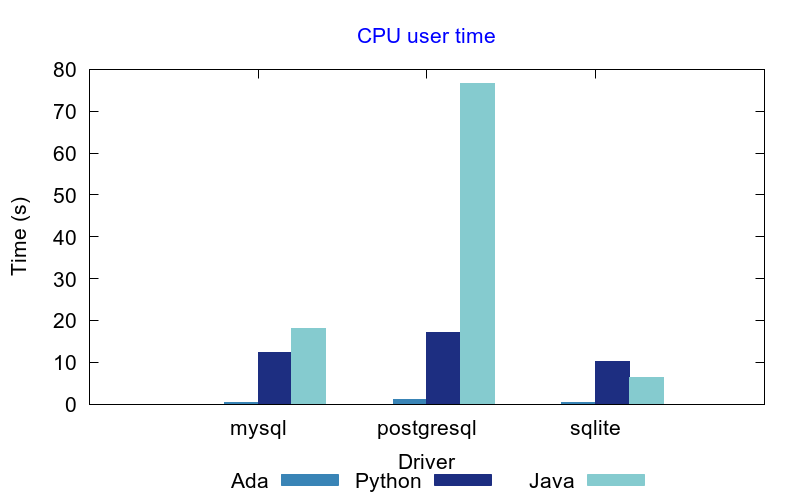
It is interesting to note however that both Java and Python provide very good performance results with SQLite database when the number of rows returned by the query is less than 100. With more than 500 rows, Ada becomes faster than others.
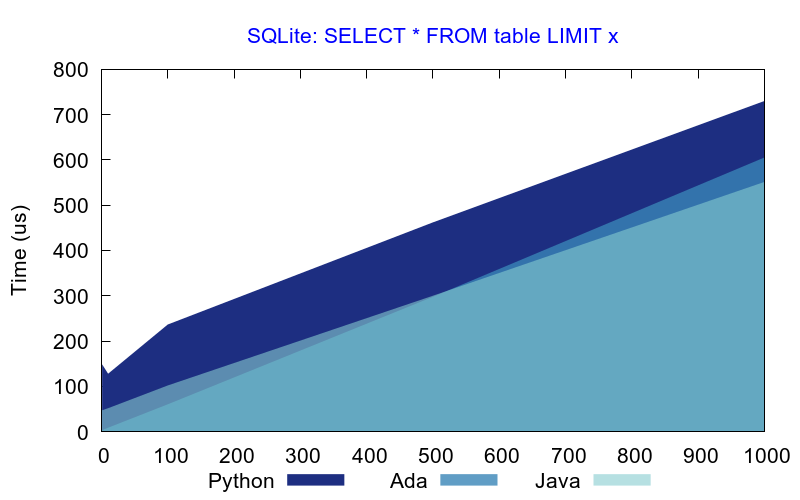
With a PostgreSQL database, Ada is always faster even with small result sets.
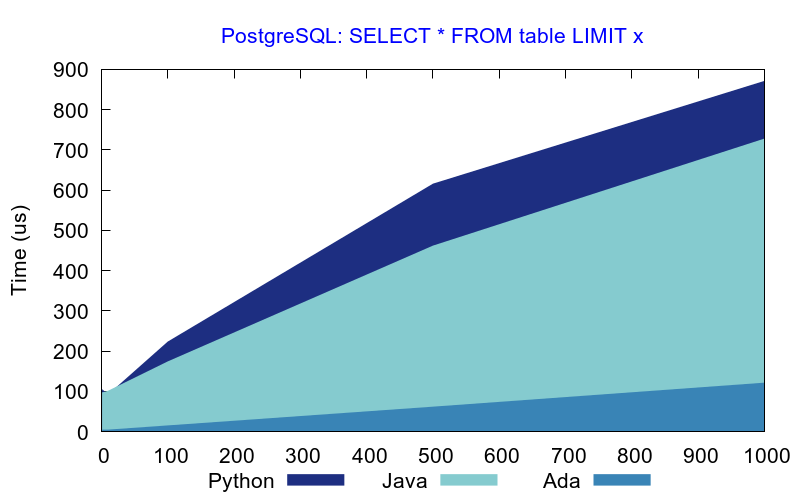
Conclusion and references
SQLite as an embedded database is used on more than 1 billion of devices as it is included in all smartphones (Android, iOS). It provides very good performances for small databases.
With client-server model, MariaDB and PostgreSQL are suffering a little when compared to SQLite.
For bigger databases, Ada provides the best performance and furthermore it appears to be more predictable that other languages (ie, linear curves).
The Excel result file is available in: sql-benchmark-results.xls
Sources of the benchmarks are available in the following GitHub repository:
Tags
- Facelet
- NetBSD
- framework
- Mysql
- generator
- files
- application
- gcc
- ReadyNAS
- Security
- binutils
- ELF
- JSF
- Java
- bacula
- Tutorial
- Apache
- COFF
- collaboration
- planning
- project
- upgrade
- AWA
- C
- EL
- J2EE
- UML
- php
- symfony
- Ethernet
- Ada
- FreeBSD
- Go
- KVM
- MDE
- Proxy
- STM32
- Servlet
- backup
- lvm
- multiprocessing
- web
- Bean
- Jenkins
- release
- OAuth
- ProjectBar
- REST
- Rewrite
- Sqlite
- Storage
- USB
- Ubuntu
- bison
- cache
- crash
- Linux
- firefox
- performance
- interview
Add a comment
To add a comment, you must be connected. Login