Ada Web Application is a complete framework that allows to write web applications using the Ada language. Through a complete web application, the tutorial explains various aspects in setting up and building an application by using AWA. The tutorial is split in several articles and they are completed by short videos to show how easy the whole process is.
The tutorial assumes that you have already installed the following software on your computer:
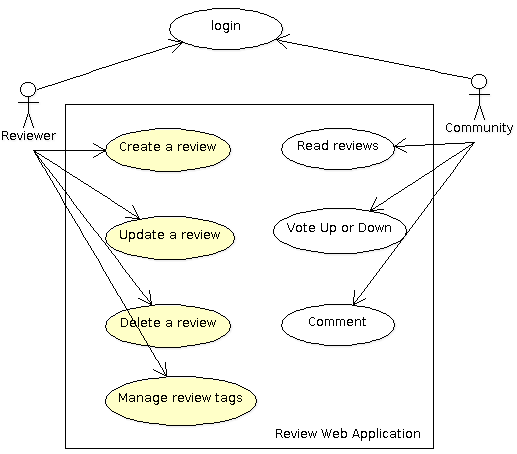
The review web application allows users to write reviews about a product, a software or a web site and share them to the Internet community. The community can read the review, participate by adding comments and voting for the reviewed product or software.
Review Web Application Use Cases
The AWA framework provides several modules that are ready to be used by our application. The login and user management is handled by the framework so this simplifies a lot the design of our application. We will see in the tutorial how we can leverage this to our review application.
Because users of our review web application have different roles, we will need permissions to make sure that only reviewers can modify a review. We will see how the AWA framework leverages the Ada Security library to enforce the permissions.
The AWA framework also integrates three other modules that we are going to use: the tags, the votes and the comments.
Since many building blocks are already provided by the Ada framework, we will be able to concentrate on our own review application module.
Project creation with Dynamo
The first step is to create the new project. Since creating a project from scratch is never easy we will use the Dynamo tool to build our initial review web application. Dynamo is a command line tool that provides several commands that help in several development tasks. For the project creation we will give:
the output directory,
the project name,
the license to be used for the project,
the project author's email address.
Choose the project name with care as it defines the name of the Ada root package that will be used by the project. For the license, you have the choice between GPL v2, GPL v3, MIT, BSD 3 clauses, Apache 2 or some proprietary license.
dynamo -o atlas create-project -l apache atlas Stephane.Carrez@gmail.com
(Of course, change the above email address by your own email address, this is an example!)
The Dynamo project creation will build the atlas directory and populate it with many files:
A set of configure, Makefile, GNAT project files to build the project,
A set of Ada files to build your Ada web application,
A set of presentation files for the web application.
Once the project is created, we must configure it to find the Ada compiler, libraries and so on. This is done by the following commands:
cd atlas
./configure
At this step, you may even build your new project and start it. The make command will build the Ada files and create the bin/atlas-server executable that represents the web application.
With the Ada Web Application framework, a web application is composed of modules where each module brings a specific functionality to the application. AWA provides a module for user management, another for comments, tags, votes, and many others. The application can decide to use these modules or not. The AWA module helps in defining the architecture and designing your web application.
For the review web application we will create our own module dedicated for the review management. The module will be an Ada child package of our root project package. From the Ada point of view, the final module will be composed of the following packages:
A Modules package represents the business logic of the module. It is provides operations to access and manage the data owned by the module.
A Beans package holds the Ada beans that make the link between the presentation layer and business logic.
A Models package holds the data model to access the database content. This package is generated from UML and will be covered by a next tutorial.
To help in setting up a new AWA module, the Dynamo tool provides the add-module command. You just have to give the name of the module, which is the name of the Ada child package. Let's create our reviews module now:
dynamo add-module reviews
The command generates the new AWA module and modifies some existing files to register the new module in the application. You can build your web application at this stage even though the new module will not do anything yet for you.
Eclipse setup
Launch you Eclipse and create the new project by going to the File -> New -> Project menu. Choose the Ada Project and uncheck the Use default location checkbox so that you can browse your file system and select the atlas directory.
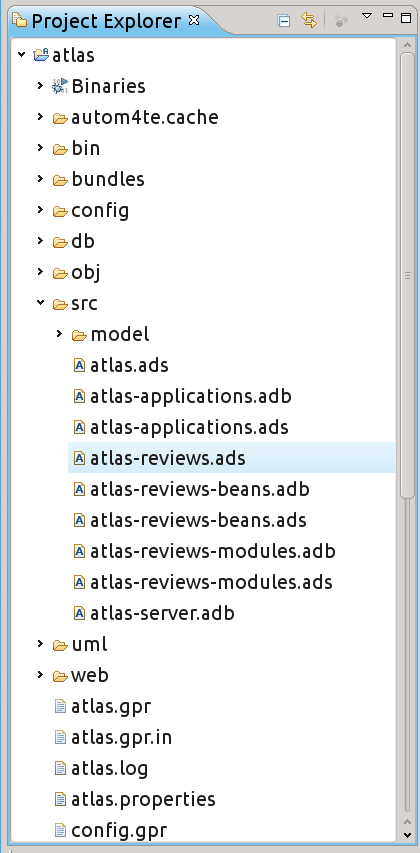
That's it. If everything went well, you should be able to see the projects files in the Eclipse project explorer.
Eclipse project explorer
The Review Web Application setup video
To help you in setting up and see how the whole process looks like in reality, I've created the following short video that details the above tutorial steps.
Conclusion
The whole process takes less than 3 minutes and gives you the basis to setup and build your new web application. The next tutorial will explain how to use the UML to design and generate the data model for our Review Web Application.
I've created and setup a Debian repository to give access to several Debian packages for several Ada projects that I manage. The goal is to provide some easy and ready to use packages to simplify and help in the installation of various Ada libraries. The Debian repository includes the binary and development packages for Ada Utility Library, Ada EL, Ada Security, and Ada Server Faces.
Access to the repository
The repository packages are signed with PGP. To get the verification key and setup the apt-get tool, you should run the following command:
A first repository provides Debian packages targeted at Ubuntu 13.04 raring. They are built with the gnat-4.6 package and depend on libaws-2.10.2-4 and libxmlada4.1-dev. Add the following line to your /etc/apt/sources.list configuration:
deb http://apt.vacs.fr/ubuntu-raring raring main
Ubuntu 12.04 LTS Precise
A second repository contains the Debian packages for Ubuntu 12.04 precise. They are built with the gnat-4.6 package and depend on libaws-2.10.2-1 and libxmlada4.1-dev. Add the following line to your /etc/apt/sources.list configuration:
deb http://apt.vacs.fr/ubuntu-precise precise main
Installation
Once you've added the configuration line, you can install the packages:
Ada Server Faces is a framework that allows to create Web applications using the same design patterns as the Java Server Faces (See JSR 252, JSR 314, or JSR 344). The presentation pages benefit from the FaceletsWeb template system and the runtime takes advantages of the Ada language safety and performance.
A new release is available with several features that help writing online applications:
Add support for Facebook and Google+ login
Javascript support for popup and editable fields
Added support to enable/disable mouseover effect in lists
New EL function util:iso8601
New component <w:autocomplete> for input text with autocompletion
New component <w:gravatar> to render a gravatar image
New component <w:like> to render a Facebook, Twitter or Google+ like button
New component <w:panel> to provide collapsible div panels
New components <w:tabView> and <w:tab> for tabs display
New component <w:accordion> to display accordion tabs
Add support for JSF <f:facet>, <f:convertDateTime>, <h:doctype>
Ada EL is a library that implements an expression language similar to JSP and JSF Unified Expression Languages (EL). The expression language is the foundation used by Java Server Faces and Ada Server Faces to make the necessary binding between presentation pages in XML/HTML and the application code written in Java or Ada.
The presentation page uses an UEL expression to retrieve the value provided by some application object (Java or Ada). In the following expression:
#{questionInfo.question.rating}
the EL runtime will first retrieve the object registered under the name questionInfo and look for the question and then rating data members. The data value is then converted to a string.
A few days ago, I did a fresh installation of my Jenkins build environment for my Ada projects (this was necessary after a disk crash on my OVH server). I took this opportunity to setup a FreeBSD build node. This article is probably incomplete but tends to collect a number of tips for the installation.
Virtual machine setup
The FreeBSD build node is running within a QEMU virtual machine. The choice of the host turns out to be important since not all versions of QEMU are able to run a FreeBSD/NetBSD or OpenBSD system. There is a bug in QEMU PCI emulation that prevents the NetBSD network driver to recognize the emulated network cards (See qemu-kvm 1.0 breaks openbsd, netbsd, freebsd). Ubuntu 12.04 and 12.10 provide a version of Qemu that has the problem. This is solved in Ubuntu 13.04, so this is the host linux distribution that I've installed.
For the virtual machine disk, I've setup some LVM partition on the host as follows:
sudo lvcreate -Z n -L 20G -n freebsd vg01
this creates a disk volume of 20G and label it freebsd.
The next step is to download the FreeBSD Installation CD (I've installed the FreeBSD-10.0-RC2). To manage the virtual machines, one can use the virsh command but the virt-manager graphical front-end provides an easier setup.
sudo virt-manager
The virtual machine is configured with:
CPU: x86_64
Memory: 1048576
Disk type: raw, source: /dev/vg01/freebsd
Network card model: e1000
Boot on the CD image
After the virtual machine starts, the FreeBSD installation proceeds (it was so simple that I took no screenshot at all).
Post installation
After the FreeBSD system is installed, it is almost ready to be used. Some additional packages are added by using the pkg install command (which is very close to the Debian apt-get command).
pkg install jed
pkg install sudo bash tcpdump
By default the /proc is not setup and some application like the OpenJDK need to access it. Edit the file /etc/fstab and add the following lines:
Jenkins uses a Java application that runs on each build node. It is necessary to install some Java JRE. To use subversion on the build node, we must make sure to install some 1.6 version since the 1.8 and 1.7 version have incompatibilities with the Jenkins master. The following packages are necessary:
Jenkins needs a user to connect to the build node. The user is created by the adduser command. The Jenkins user does not need any privilege.
Jenkins master will use SSH to connect to the slave node. During the first connection, it installs the slave.jar file which manages the launch of remote builds on the slave. For the SSH connection, the password authentication is possible but I've setup a public key authentication that I've setup on the FreeBSD node by using ssh-copy-id.
At this stage, the FreeBSD build node is ready to be added on the Jenkins master node (through the Jenkins UI Manage Jenkins/Manage Nodes).
MySQL Installation
The MySQL installation is necessary for some of my projects. This is easily done as follows:
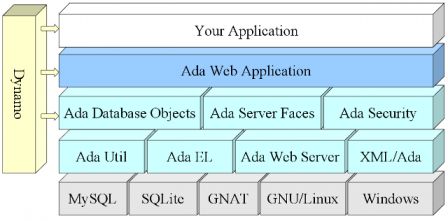
AWA uses Ada Server Faces for the web framework. This framework is using several patterns from the Java world such as Java Server Faces and Java Servlets.
AWA provides a set of ready to use and extendable modules that are common to many web application. This includes managing the login, authentication, users, permissions.
AWA uses an Object Relational Mapping that helps in writing Ada applications on top of MySQL or SQLite databases. The ADO framework allows to map database objects into Ada records and access them easily.
AWA is a model driven engineering framework that allows to design the application data model using UML and generate the corresponding Ada code.
Ada Web Application Architecture, fév. 2013
The new version of AWA provides:
New jobs plugin to manage asynchronous jobs,
New storage plugin to manage a storage space for application documents,
New votes plugin to allow voting on items,
New question plugin to provide a general purpose Q&A.
Dynamo is a tool to help developers write some types of Ada Applications which use the Ada Server Faces or Ada Database Objects frameworks. Dynamo provides several commands to perform one specific task in the development process: creation of an application, generation of database model, generation of Ada model, creation of database.
The new version of Dynamo provides:
A new command build-doc to extract some documentation from the sources,
The generation of MySQL and SQLite schemas from UML models,
The generation of Ada database mappings from UML models,
The generation of Ada beans from the UML models,
A new project template for command line tools using ADO,
A new distribution command to merge the resource bundles.
The most important feature is probably the Ada code generation from a UML class diagram. With this, you can design the data model of an application using ArgoUML and generate the Ada model files that will be used to access the database easily through the Ada Database Objects library. The tool will also generate the SQL database schema so that everything is concistent from your UML model, to the Ada implementation and the database tables.
The short tutorial below indicates how to design a UML model with ArgoUML, generate the Ada model files, the SQL files and create the MySQL database.
The Ada Database Objects is an Object Relational Mapping for the Ada05 programming language. It allows to map database objects into Ada records and access databases easily. Most of the concepts developped for ADO come from the Java Hibernate ORM. ADO supports MySQL and SQLite databases.
The new version brings:
Support to reload query definitions,
It optimizes session factory implementation,
It allows to customize the MySQL database connection by using MySQL SET
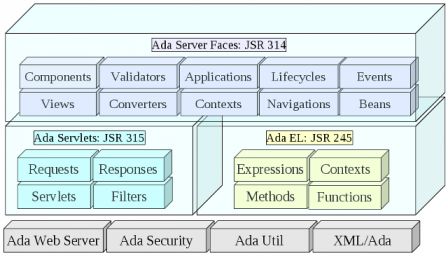
Ada Server Faces is an Ada implementation of several Java standard web frameworks.
The Java Servlet (JSR 315) defines the basis for a Java application to be plugged in Web servers. It standardizes the way an HTTP request and HTTP response are represented. It defines the mechanisms by which the requests and responses are passed from the Web server to the application possibly through some additional filters.
The Java Unified Expression Language (JSR 245) is a small expression language intended to be used in Web pages. Through the expressions, functions and methods it creates the link between the Web page template and the application data identified as beans.
The Java Server Faces (JSR 314 and JSR 344) is a component driven framework which provides a powerful mechanism for Web applications. Web pages are represented by facelet views (XHTML files) that are modelized as components when a request comes in. A lifecycle mechanism drives the request through converters and validators triggering events that are received by the application. Navigation rules define what result view must be rendered and returned.
Ada Server Faces gives to Ada developers a strong web framework which is frequently used in Java Web applications. On their hand, Java developers could benefit from the high performance that Ada brings: apart from the language, they will use the same design patterns.
Ada Server Faces, fév. 2013
The new version of Ada Server Faces is available and brings the following changes:
The Security packages was moved in a separate project: Ada Security,
New demo to show OAuth and Facebook API integration,
Integrated jQuery 1.8.3 and jQuery UI 1.9.2,
New converter to display file sizes,
Javascript support was added for click-to-edit behavior,
Add support for JSF session beans,
Add support for servlet error page customization,
Allow navigation rules to handle exceptions raised by Ada bean actions,
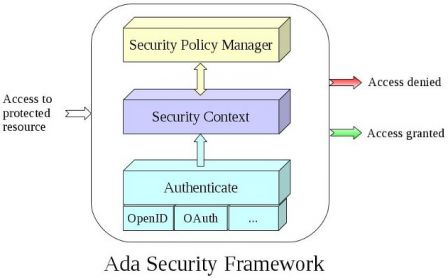
Ada Security is a security framework which allows web applications to define and enforce security policies. The framework allows users to authenticate by using OpenID Authentication 2.0. Ada Security also defines a set of client methods for using the OAuth 2.0 protocol.
Ada Security Framework, janv. 2013
A security policy manager defines and implements the set of security rules that specify how to protect the system or the resources.
A user is authenticated in the application. Authentication can be based on OpenID or another system.
A security context holds the contextual information that allows the security policy manager to verify that the user is allowed to access the protected resource according to the policy rules.
The Ada Security framework can be downloaded at Ada Security project page.
AWA is architectured arround modules and plugins that allow to build, re-use and extend modules made of Ada code, Web pages or Javascript.
AWA provides a set of ready to use and extendable plugins that are common to many web application. This includes managing the login, authentication, users, permissions, a mail plugin, a blog plugin, a Javascript light editor.
AWA uses an Object Relational Mapping that helps in writing Ada applications on top of MySQL or SQLite databases. The ADO framework allows to map database objects into Ada records and access them easily.
AWA integrates a configurable event service which allows plugins to easily interact and connect with each other (either synchronously or asynchronously). The event service provided by AWA is heavily inspired from the Java Message Service.
To learn more on how to create easily a web application using AWA, look at the 4 minutes video.
The Atlas Web Application Demonstrator is a demonstration of an application using this AWA framework. Sources of the Atlas demonstrator are available on GitHub project: Atlas.
Dynamo is a tool to help developers write an Ada Web Application using the Ada Server Faces and the Ada Database Objects frameworks. Dynamo provides several commands to perform one specific task in the development process: creation of an application, generation of database model, generation of Ada model, creation of database.
The new version of Dynamo provides:
Support multi-line comments in XML mappings,
Generate List_Bean types for the XML mapped queries,
Add support for Ada enum generation,
Add test template generation,
Add AWA service template generation,
Add support for blob model mapping,
New command 'add-ajax-form', 'add-query', 'dist', 'create-plugin'
The Ada Database Objects is an Object Relational Mapping for the Ada05 programming language. It allows to map database objects into Ada records and access databases easily. Most of the concepts developped for ADO come from the Java Hibernate ORM. ADO supports MySQL and SQLite databases.
The new version brings:
Support to update database records when a field is really modified,
Customization of the SQLite database connection by using SQLite PRAGMAs,